Extensive materials now published on GitHub!
The second edition of the block course Deep Learning with Actuarial Applications in R took place a couple of weeks ago, and we would like to look back and highlight a few key takeaways.
First of all, research is still very much a continuous work in progress in this field, so it should not come as a surprise that the second half of the course was completely new compared to last year’s first edition.
The introductory first day with GLM, Feed-forward Neural Networks (FNN) and discrimination-free pricing once more laid a solid foundation for all to approach these topics. On the second day, actuaries got an introduction to a new specific network architecture called local GLM net. This FNN extension marks an important step forward in applying deep learning techniques in an interpretable manner that nicely relates to traditional regression models, improving both understanding and explainability. It can be more easily compared and analyzed in terms of aspects such as feature importance or covariate interactions, ultimately allowing for comprehensible variable selection. A new chapter on convolutional neural networks (CNN) rounded off the course and gave some basic examples on analyzing images or time series data.
I know that many people will be thrilled to hear that materials from the course have been published and made available to everyone in a new dedicated GitHub repository! The interesting (albeit somewhat heavy) Recurrent Neural Networks (RNN) topic from the 2020 edition can also be found there. In addition, it is worth mentioning the Tutorials section of the data science working group of the Swiss Actuarial Association, which served as the foundation for the course and where you can find a couple of other extra topics.
The complete set of materials provides a compelling toolkit and invaluable guidance to both beginners and more experienced practitioners.
The exercises with fully working code have been enriched with detailed comments, links to the theoretical background, and actual questions to motivate readers to explore some topics on their own and develop a better feel for the complexity, nuances, pitfalls - and of course network architecture and hyperparameters.
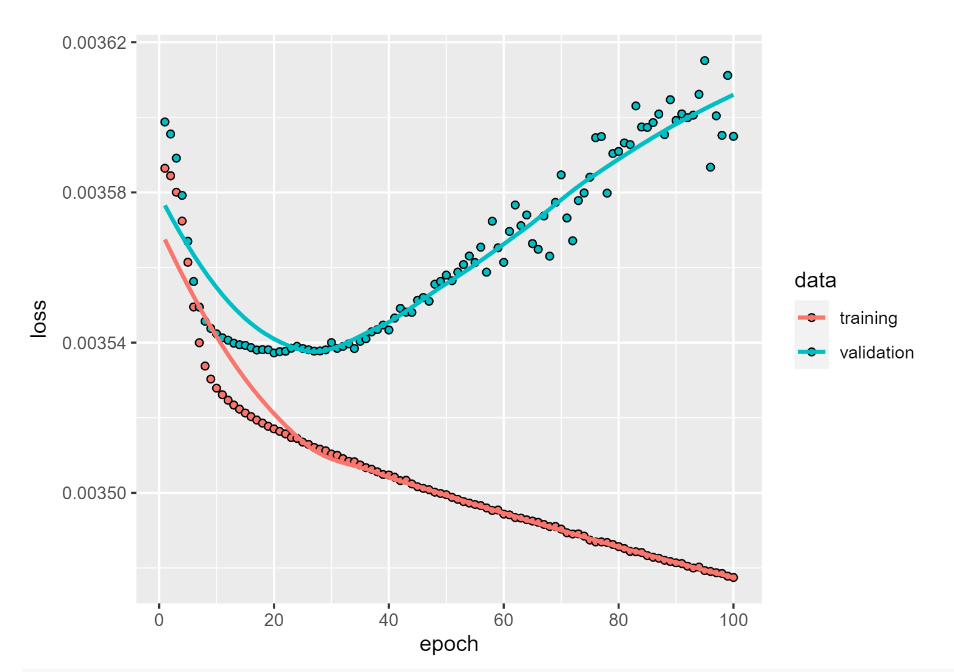
If you would like to run the code, we recommend the Rmarkdown files (also used during the courses). Keep in mind that you will have to install all the necessary dependencies first, in particular fully working recent versions of keras and tensorflow (we used 2.6), which is fairly easier to set up on a Ubuntu / Linux machine than on Windows. Another option is to just look at the resulting html files that you can find alongside in the GitHub repository, or if you feel like following in our footsteps maybe give the hosted Renku service a try.
Getting started with the exercises on the SDSC’s Renku platform went smoothly as expected, even if some of the participants’ sessions took a bit longer to be fully up and running on the Kubernetes cluster. In preparation for this workshop we created two projects on Renku, one as a base to capture all the necessary dependencies such as system libraries and R packages, and the other main project with all of the notebooks and actual workshop content. The Dockerfile in the latter is then built from the Dockerfile of the former. This setup only requires users to fork the main project, while sharing underlying docker images, thus reducing startup time by not having to rebuild / reinstall all packages and dependencies from scratch.